Approximation - adding, running and deleting projects¶
Adding a new project¶
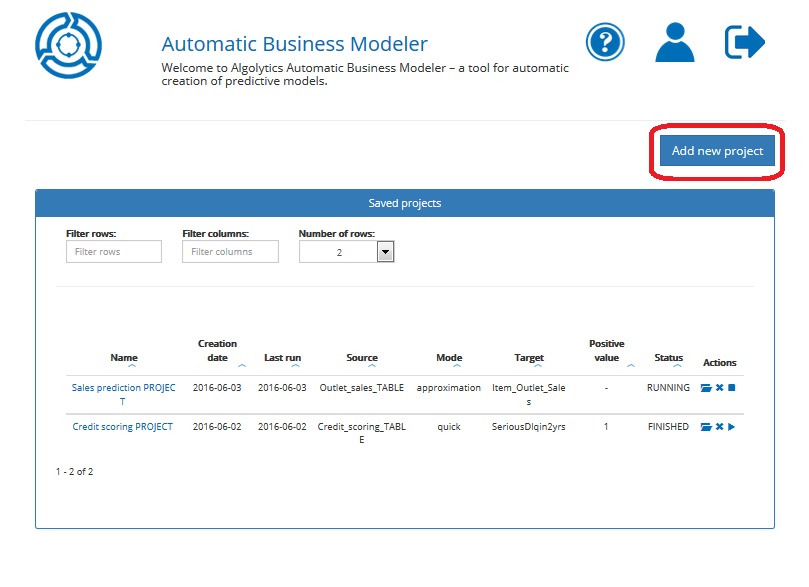
In order to create a new project, go to the Homepage and click the Add new project button.
In the next five steps you will be asked to:
Step 1: Enter the name for your project and select a problem category
Step 2: Select a source dataset
Step 3: Enter variables settings
Step 4: Enter building model process settings
Step 5: Check if the information provided is correct
In the next chapters, you will learn how to specify the settings of your projects with reference to the above steps.
Step 1: Naming a new project and selecting a problem category¶
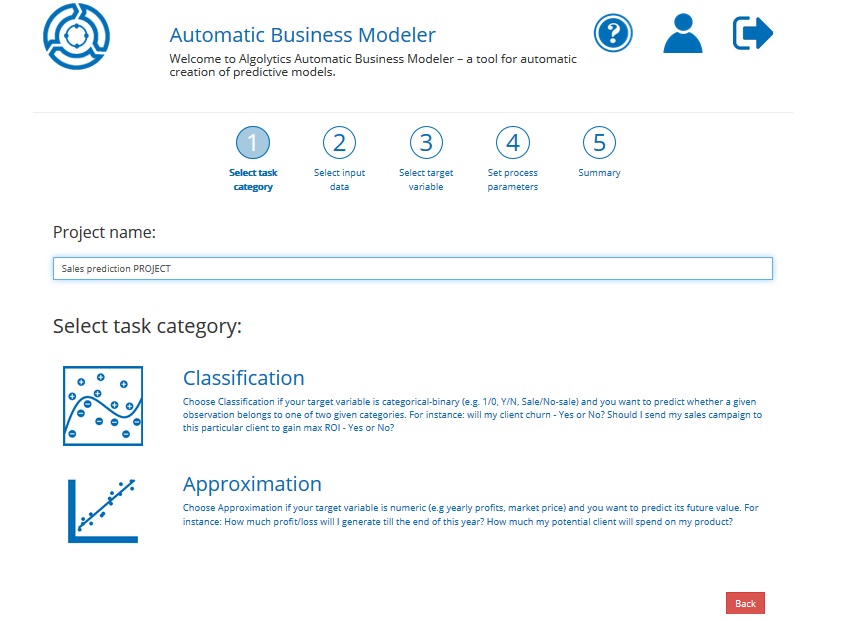
In the first field, enter a project name (something easy to remember).
Remark: The project name should be no longer than 32 characters
Click Approximation in order to proceed to the next step.
Step 2: Selecting a source dataset¶
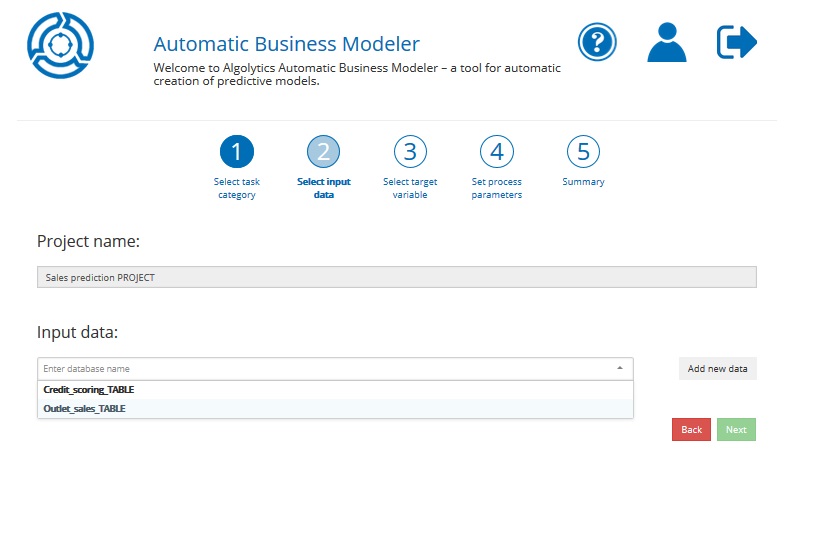
Indicate the dataset that will be used to build your model. You can do this by choosing already imported files from the list. If there is no data available or you want to import new data, click the Add new data button and follow the steps described in the Chapter Importing files.
Click the Next button to proceed.
Step 3: Entering variables settings¶
In this step you will be asked to:
- Choose a target variable (e.g. TARGET)

- (optional) you can impose how ABM ought to use selected variables by indicating their type (ACTIVE, INACTIVE, OBLIGATORY, ID) and/or role (CATEGORICAL, NUMERICAL)
Here is a short description of what particular types and roles mean:
- ACTIVE: if a variable is active, it means that it will be taken into account during the model building process (but it doesn’t mean it will be selected for the model)
- INACTIVE: if a variable is inactive, it means that it will be ignored during the model building process
- OBLIGATORY: if a variable is obligatory, it means that it will be chosen during the feature selection stage, but not necessarily included in the final model
- ID: ID variable is a variable with unique values used for identification of observations (e.g. customer ID). In the scoring process, scoring points will be assigned to the ID variable
- CATEGORICAL: is a variable that takes a value that is one of several possible categories (e.g. gender, occupation, eye colour). Categorical variables have no numerical meaning
- NUMERICAL: is a variable naturally measured as a number (e.g. age, income, temperature) for which an arithmetic operation can be applied
In order to assign a specific type and/or role to selected variable(s):
- Filter rows, to see only selected variable(s)
- Choose from the list role and/or type that a single variable(s) should have
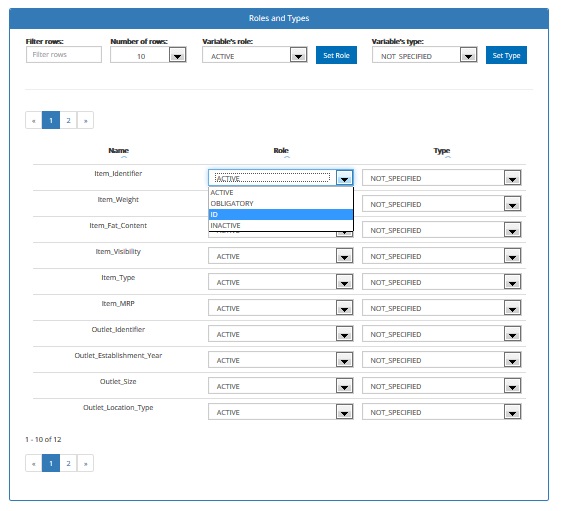
If you want to set a specific type/role to multiple variables:
- Filter rows, to see only selected variables
- Choose from the list role and/or type that selected variables should have
- Click Set Role and/or click Set Type button to make changes
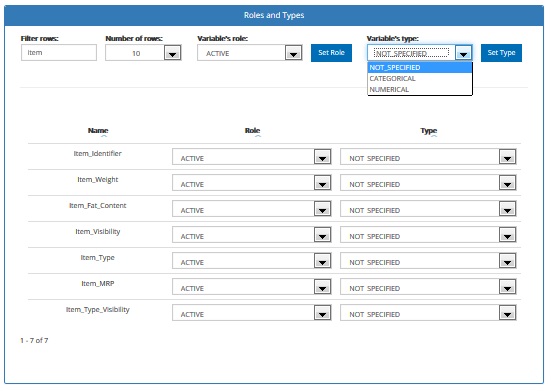
Click the Next button if you want to proceed or the Back button if you want to change the previous project settings.
Step 4: Building model process settings¶
In this step, you will be asked to enter various settings that specify the modelling process.
- Approximation model quality measure: the user can select the best way of measuring model quality (default: MEAN ABSOLUTE ERROR)
- MEAN ABSOLUTE ERROR: the mean absolute error (MAE) is a quantity used to measure how close are the predictions to the real target values. This statistic takes a value between 0 and infinity. The closer to 0, the better is the model quality
- MEAN ABSOLUTE PERCENTAGE ERROR: the mean absolute percentage error (MAPE) is a measure of prediction accuracy. This statistic takes a value between 0 and 1 (or 0 - 100%). The closer to 0, the better is the model quality
- ROOT MEAN SQUARE ERROR: the root-mean-square error (RMSE) is another measure of the prediction accuracy. It represents the sample standard deviation of the differences between the predictions and the real target values. This statistic takes a value between 0 and infinity. The closer to 0, the better is the model quality
- R-SQUARED: the coefficient of determination, denoted R2 (R-squared), is a measure that indicates the proportion of the variance in the predicted target variable that is explained by the model. It gives information about the goodness of fit of a model. This statistic takes a value between 0 and 1 (or 0 - 100%). The closer to 1, the better is the model quality. A value of 1 means the model perfectly fitted, a value of 0 means the model doesn’t explain the data

- (advanced settings) Sampling Mode: determines the sample selection method during the data sampling stage. The user sets the sample size manually.

- (advanced settings) Sample size: the user enters the sample size in this field. The default setting is 30 000

Click the Next button if you want to proceed or the Back button if you want to change the previous project settings.
Step 5: Summary¶
You are almost ready to build a predictive model with ABM. In this final step, check whether all information provided in Steps 1,2,3,4 is correct.
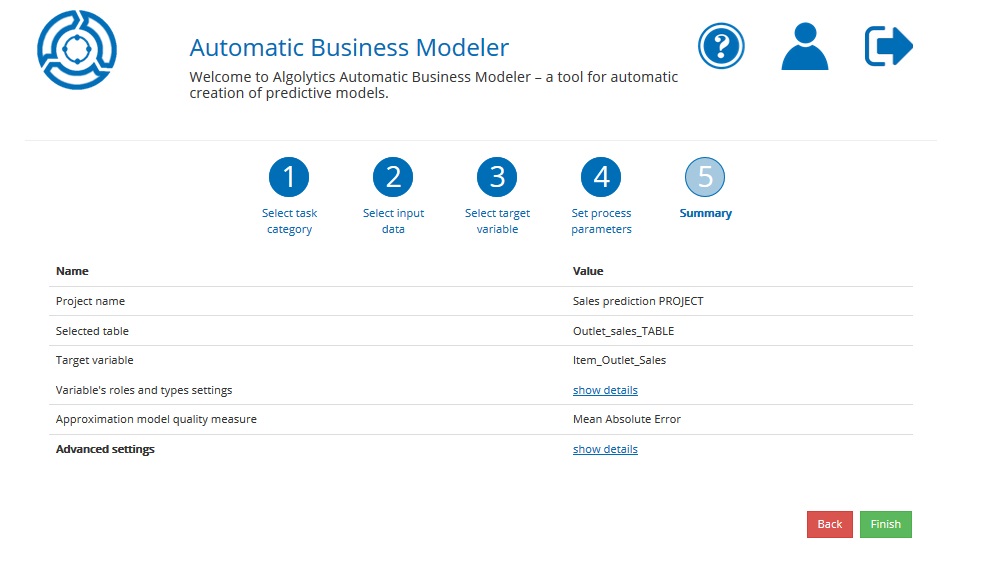
If you have no remarks, click the Finish button. If not, click the Back button to make changes.
Running a project¶
After setting project parameters and clicking the Finish button you will be sent to a webpage where you can run the project. Just click the Run button.
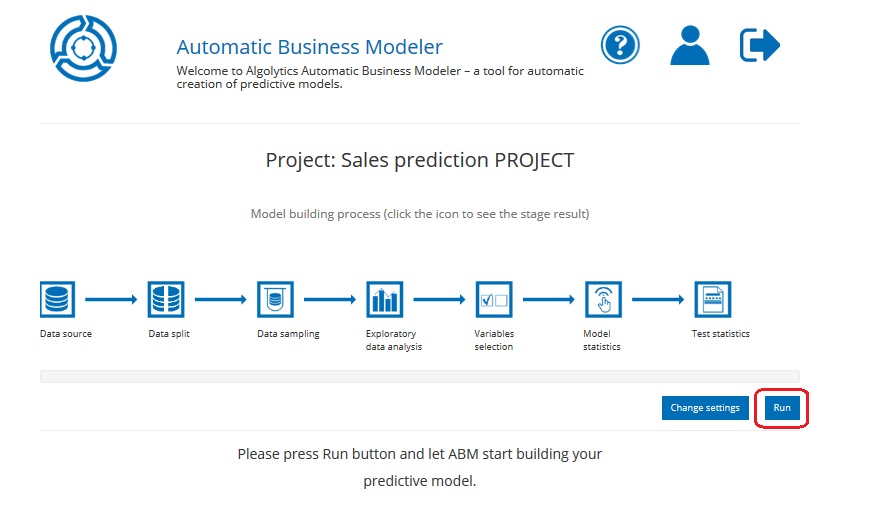
You can also run a project from the Homepage by clicking the Run project button.
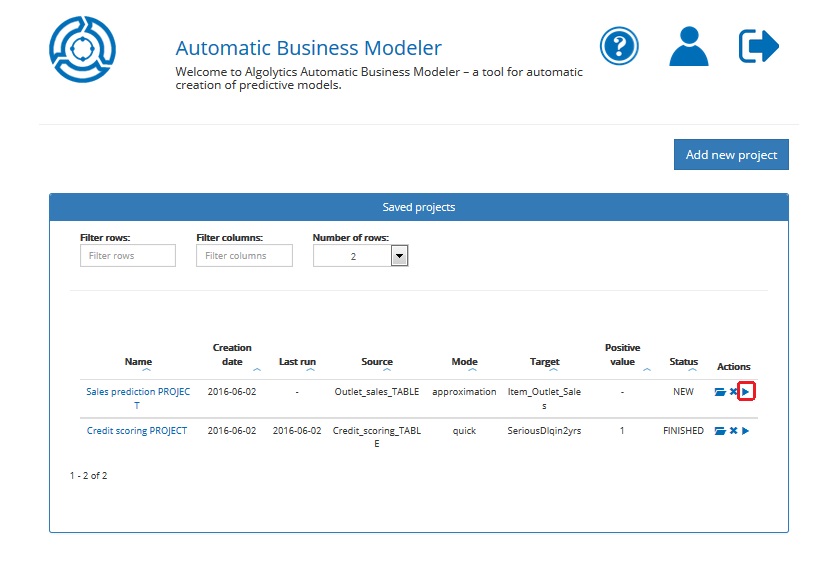
The model building may take a while, nevertheless, you can explore the report concerning the particular process stage as soon as ABM finishes calculating its statistics. Open the project by clicking on its name and then click the icon to see the stage result.
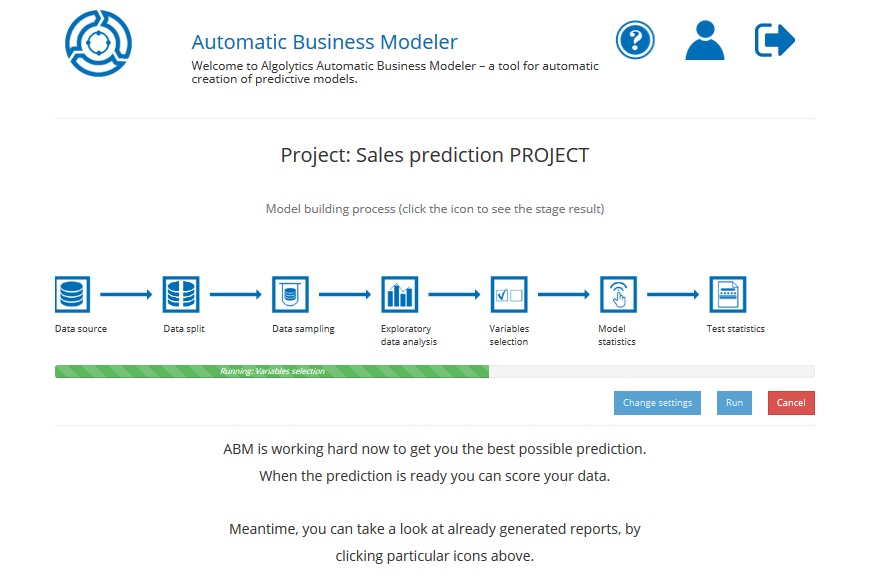
You can monitor the progress of calculating the model thanks to the progress bar available after opening the project.
After your predictive model is built, you can score a new data or download a scoring code.
Remarks If you wanted to re-run your project, source data should be available in the Repository (Files imported to Repository). Otherwise the project is in the read-only status. You can explore its reports and score data but can’t run it.
Changing project settings¶
Sometimes you may come to the conclusion that the settings of the project you have just added are not right and you wish to change them. You can do this before running the process:
- From the Homepage, click the Open project button or click the project name
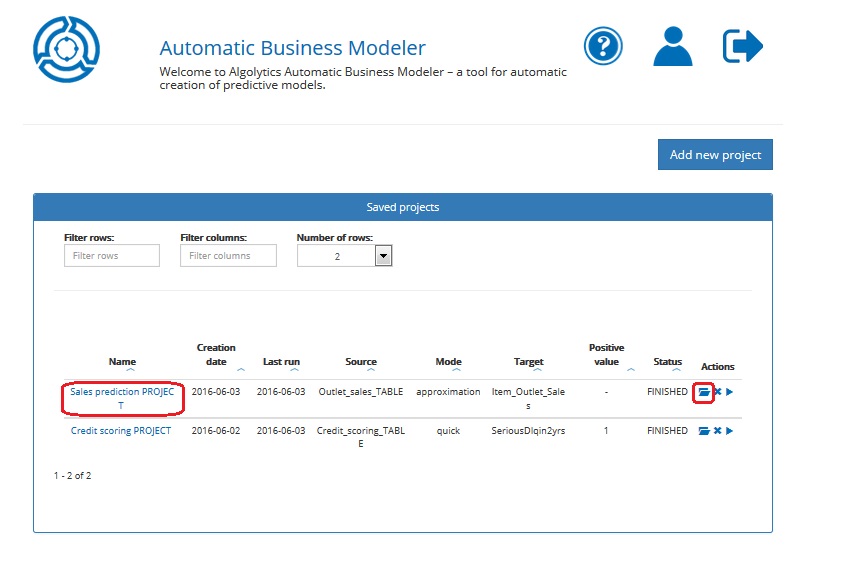
- Click the Change settings button and follow Steps 1,2,3,4,5 described in previous chapters
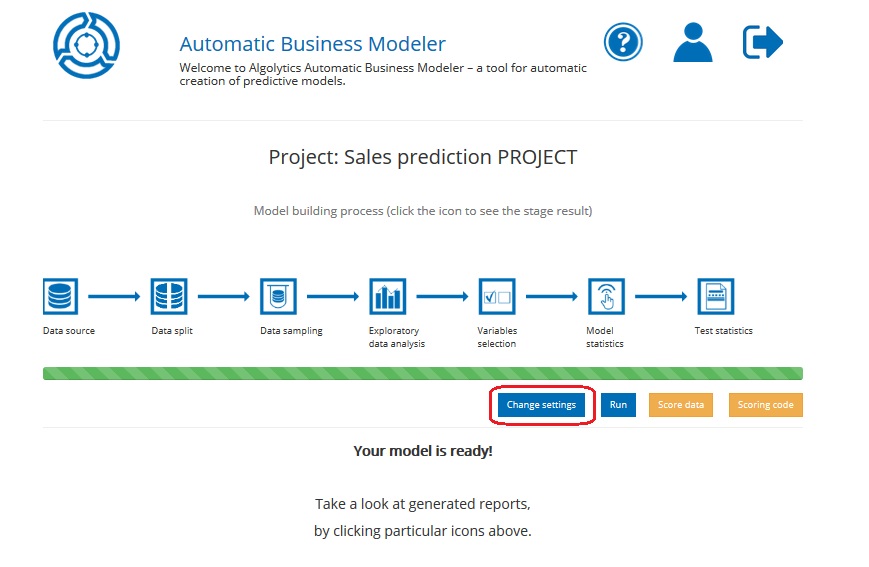
Remark: You can also change settings after the model is built to check how it performs with other parameters. However, to avoid overwriting already received results, we suggest adding another project with new parameters and comparing the models built within both projects.
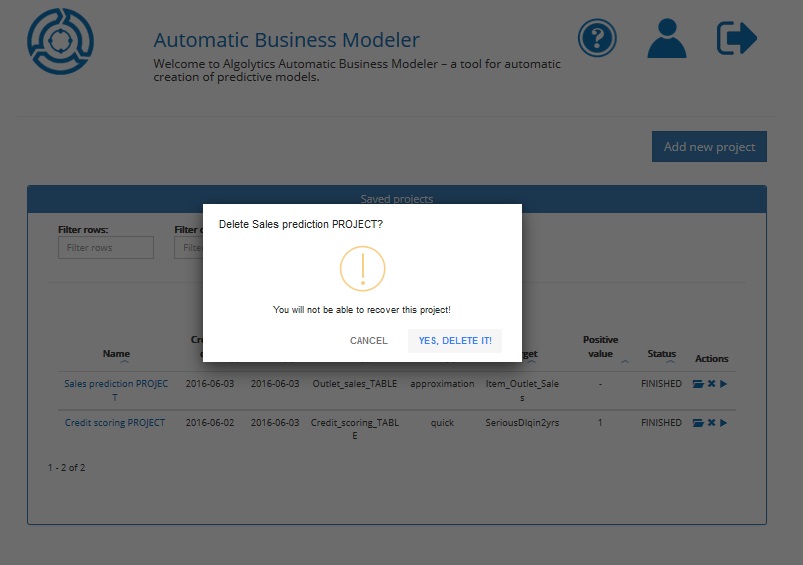
Deleting a project¶
In order to delete a project, click the Delete button available from the Homepage.
You will be asked for confirmation.