Introduction to ABM¶
What is Automatic Business Modeler?¶
Automatic Business Modeler is a tool for automatic construction and updating of predictive models. It provides full automation of essential, yet time-consuming activities in model construction, such as fast variable selection, variable interaction modelling, and variable transformations or best model selection.
Automatic Business Modeler includes integrated analytical and business knowledge, gained by our company during 14 years of undertaking data mining projects for various industries. The system was developed in cooperation with the Institute of Computer Science, Polish Academy of Sciences and scientists in the field of statistical data analysis. ABM was co-financed by the European Regional Development Fund under the Operational Programme Innovative Economy.
ABM’s main features¶
Enables building of classification and approximation models with a binary target (based on selected source data and process parameters)
- Provides three working modes (for classification models) presenting different approaches to data processing and modelling:
- The Quick mode: enables obtaining an accurate model in a relatively short time
- The Advanced mode: uses more advanced methods for feature selection and data preparation
- The Gold mode: provides a more in-depth search through possible predictive modelling paths, therefore requiring more time for the modelling process
Imports data from .csv files (other data source formats are planned)
- Automates the following steps of the predictive model building process:
- Data sampling
- Handling/imputation of the missing values
- Variables selection
- Handling of correlated variables
- Variables transformations
- Creating variables interactions
- Handling of outliers
- Application of a variety of advanced models with optimised settings
- Consideration of time instability of the modelled event
- Choosing the best model based on various statistical measures
Generates reports with statistics concerning particular stages of the model building process. These reports are there to show the outcomes and quality of a model, to explain what data are used in the model, and what influence they have on the predicted event. You can see how good the predictive model is, how much better the prediction is when compared to a random selection, if it’s stable enough etc.
The reports cover, for instance, the number of positive target in the training, validation, and testing datasets, nulls count, box plot, standard deviation, variable minimum value, variable maximum value, discrete count, mode percent, coefficient, standard coefficient, KS Statistics, ROC Area, Gini Coefficient, F1 Score, Captured Response, Lift, R-square, MAE, MAPE and more.
- Enables data scoring (based on the previously built predictive model), so you can apply the prediction to new data (e.g. score new customers). As a result, an output file is generated with information such as:
- predicted target value
- the probability of a positive value of the target variable (classification models)
Generates scoring code so you can deploy a model in your database or scoring system. This feature is useful when you want to make predictions in real time.
Available through an easy to use web-based interface (Software as a Service). No need to install anything
How does it work?¶
ABM enables you to carry out the following steps, automatically:
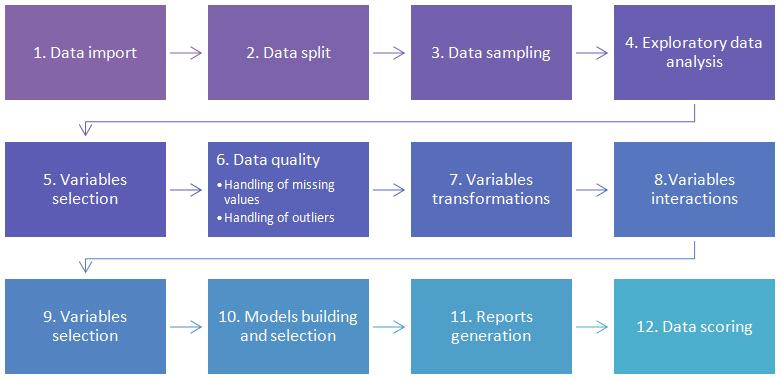
Here is a short description of each step:
- Data import: in order to create a predictive model, first ABM imports a source dataset with target and predictive variables
- Data split: the imported dataset is randomly split into three categories (training, validation, and testing data)
- Data sampling: ABM draws a sample from the data. It is possible to choose the sampling size manually or to have it done automatically. It is also possible to perform undersampling / oversampling if there are not enough positive target values in the data to perform efficient modelling
- Exploratory data analysis: in this step ABM analyses the basic properties of the data, for instance: median, mode percent, standard deviation, maximum and minimum values, quartiles
- Variables selection: a subset of variables with the highest impact on the predicted event is selected
- Data Quality: this step covers a range of data quality improvement tasks, including handling/imputation of missing values and handling of outliers (observations with unusual values that can have a substantial effect on the fitted model)
- Variables transformations: ABM selects the optimal transformation for each variable in order to maximise its predictive power
- Variables interactions: ABM calculates new variables that model the joint influence of 2 or more variables on the dependent variable. This helps to model the nonlinear dependencies in the data
- Variables selection: a subset of variables with the highest impact on the predicted event is selected
- Models building and selection: ABM builds a set of data mining models and chooses the best one based on various statistical measures (e.g. Precision, Recall, Accuracy, Lift, Captured response and more)
- Reports generation: after accomplishing each step, reports summarising the process results are generated
- Data scoring: finally, ABM scores data selected by you or generates a scoring code
Regardless of your choice, ABM will ask you for some information before it runs the model building and scoring processes, such as:
- Source file for the model building and scoring processes, including information about used separators and encoding
- Which working mode (Quick, Advanced, Gold) you want to use
- Target variable’s name and the positive target value
- Roles and types of the selected variables
- Model building process parameters
- ID variable name (predicted target values will be assigned to this variable)
Working with ABM¶
Below you will find basic steps of models building and data scoring in ABM.
Upload a file with the source dataset
Import file to the ABM internal database
2.1 Choose a file for import
2.2 Enter data import settings
2.3 Name the table in the ABM database
2.4 Check if the information provided is correct
Add new project
3.1 Enter the name of your project and select the task category
3.2 Select source dataset
3.3 Enter variables settings
3.4 Enter settings for model building process
3.5 Check if the information provided is correct
Run the project
Check the variables and predictive models statistics
Generate a scoring code or…
Score new data, if you are satisfied with the predictive model
7.1 Select file for scoring
7.2 Input detailed information about the file selected for scoring
7.3 Select threshold (for classification models)
7.4 Choose ID variable(s)
7.4 Start the data scoring process
7.5 Download scoring result
Homepage overview¶
After logging onto ABM you will see the Homepage (example shown above) where you can start creating and managing your projects.
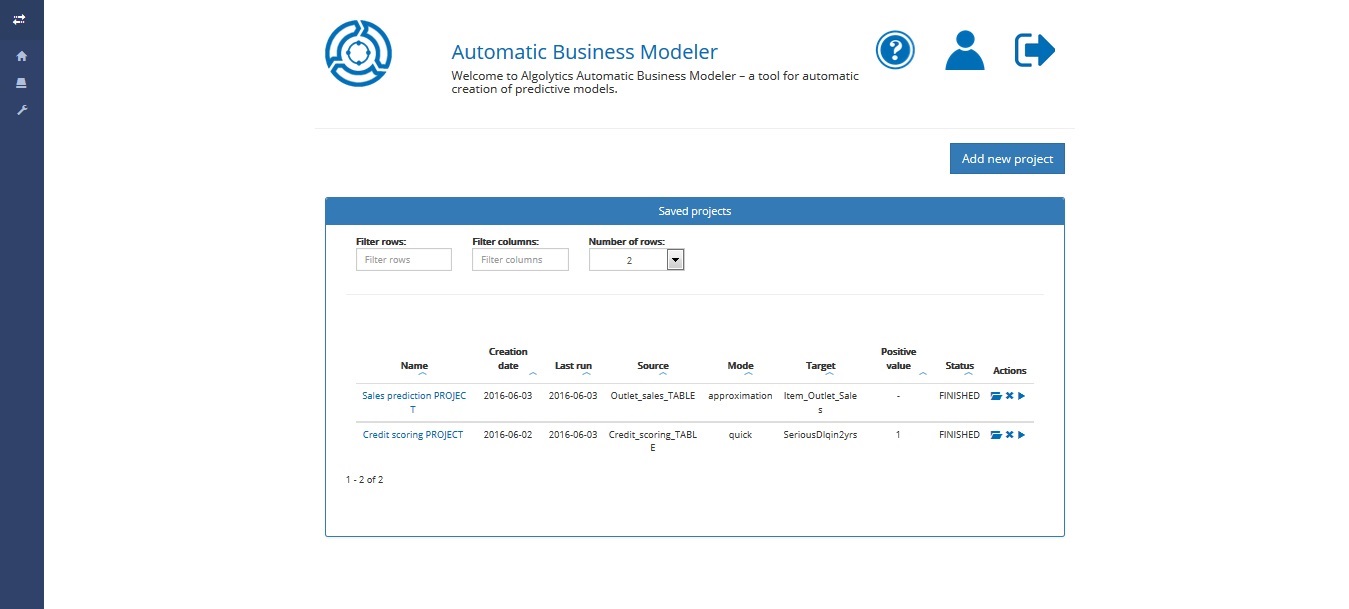
Left menu
- ABM Homepage
- Repository with all uploaded and imported files as well as files with scoring results
Upper menu
- ABM Homepage
- ABM tutorials
- Account (click the icon to change the information you provided while signing up)
- Logout
Are you ready to start building predictive models? Just click the “Add new project” button and go to the chapter Adding a new project for instructions.